Hive的壓縮格式與數據存儲格式 優化數據處理與存儲服務
在大數據生態系統中,Apache Hive作為基于Hadoop的數據倉庫工具,廣泛應用于數據查詢、分析和處理。其數據處理效率與存儲成本直接受到壓縮格式和存儲格式的影響。合理選擇壓縮和存儲格式,可以顯著提升查詢性能、降低存儲開銷,并優化數據處理與存儲服務。
一、Hive的數據存儲格式
數據存儲格式決定了數據在HDFS上的組織方式,影響讀寫速度、壓縮效率和查詢性能。常見的存儲格式包括:
- 文本格式(TextFile):
- 默認格式,以純文本形式存儲,如CSV或JSON。
- 優點:人類可讀,兼容性好。
- 缺點:存儲空間大,查詢性能低,不支持分片。
- 序列文件格式(SequenceFile):
- 二進制鍵值對存儲格式,適用于MapReduce作業。
- 優點:支持分片和壓縮,適合小文件合并。
- 缺點:非列式存儲,查詢效率有限。
- 列式存儲格式:
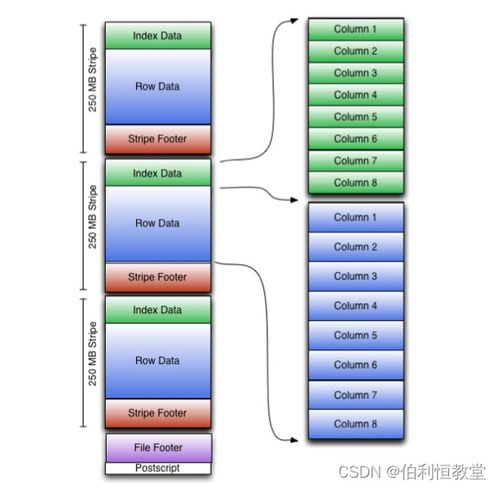
- ORC(Optimized Row Columnar):Hive原生格式,結合行和列存儲優勢,支持索引、壓縮和謂詞下推,大幅提升查詢速度。
- Parquet:跨平臺列式存儲格式,兼容Spark、Impala等工具,支持高效壓縮和嵌套數據結構。
- 優點:僅讀取查詢所需的列,減少I/O;高壓縮比;適合聚合查詢。
- 適用場景:數據倉庫、分析型負載。
- Avro格式:
- 基于JSON模式的二進制格式,支持數據序列化和動態模式演化。
- 優點:模式與數據一起存儲,兼容性好,適合數據交換。
- 缺點:查詢性能不如列式格式。
二、Hive的壓縮格式
壓縮格式用于減少存儲空間和網絡傳輸開銷,但可能增加CPU計算負載。Hive支持多種壓縮編解碼器:
- Gzip:
- 壓縮率高,但壓縮和解壓速度較慢,不支持分片。
- 適合冷數據存儲或對存儲空間敏感的場景。
- Snappy:
- 壓縮速度極快,壓縮率適中,支持分片(與存儲格式結合時)。
- 適合需要快速讀寫的數據處理管道,如實時分析。
- LZO:
- 壓縮速度與Snappy類似,支持分片,但需額外索引文件。
- 適用于Hadoop生態中的中間數據存儲。
- Bzip2:
- 壓縮率最高,但速度最慢,CPU消耗大。
- 適合歸檔存儲,極少用于生產查詢。
三、壓縮與存儲格式的搭配優化
在實際數據處理與存儲服務中,需根據業務需求平衡性能、存儲和兼容性:
- 高性能查詢場景:建議使用ORC或Parquet格式,搭配Snappy壓縮。列式存儲減少I/O,Snappy提供快速解壓,適合交互式查詢。
- 高壓縮存儲場景:選擇ORC格式(或Parquet)搭配Zlib(或Gzip)壓縮,顯著降低存儲成本,適用于歷史數據歸檔。
- 數據交換與兼容場景:Avro格式搭配Snappy壓縮,確保模式靈活性和傳輸效率。
- 實時處理流水線:可選用Parquet+Snappy,兼顧分析性能和寫入速度。
四、實踐建議
- 測試驅動選擇:在部署前,使用實際數據集測試不同組合的查詢速度、壓縮比和資源消耗。
- 分區與分桶:結合存儲格式,合理設計分區和分桶策略,進一步提升查詢效率。
- 監控與調整:持續監控集群性能,根據數據增長和查詢模式調整格式與壓縮策略。
###
Hive的壓縮格式和數據存儲格式是構建高效數據處理與存儲服務的核心要素。通過深入理解各類格式的特性,并結合業務場景進行優化組合,企業可以顯著提升大數據平臺的處理能力,同時控制成本,為數據分析與決策提供堅實基礎。
如若轉載,請注明出處:http://m.leapsoul.cn/product/21.html
更新時間:2026-05-30 00:53:59