將數據庫性能提升100倍?一位數據庫老兵在大數據時代的創新征程
在大數據浪潮洶涌澎湃的今天,數據處理與存儲服務的需求呈指數級增長。傳統的數據庫架構在面對海量、高并發的業務場景時,常常顯得力不從心,性能瓶頸成為制約企業數字化轉型的關鍵因素。在這樣的背景下,一位深耕數據庫領域數十年的老兵,憑借對底層技術的深刻理解與不懈探索,開啟了一場旨在將數據庫性能提升百倍的創新之旅。
這位老兵親歷了從關系型數據庫的黃金時代到NoSQL、NewSQL的興起,深知性能提升絕非簡單的參數調優或硬件堆砌。他意識到,真正的突破必須從架構層面進行革新。于是,他帶領團隊將目光投向了存儲引擎、查詢優化器、并發控制等核心組件,并大膽引入了現代硬件特性與分布式系統理論。
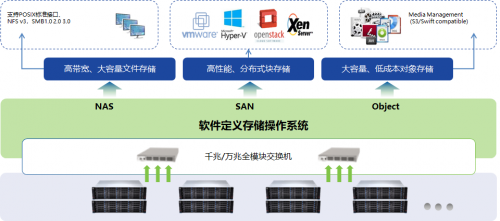
他們重新設計了存儲引擎。通過采用持久化內存(PMem)與高速NVMe SSD的混合存儲架構,并結合創新的數據布局與壓縮算法,實現了相比傳統磁盤陣列數十倍的I/O吞吐量與極低的訪問延遲。利用向量化執行與即時編譯(JIT)技術,讓查詢處理不再逐行進行,而是以數據塊為單位進行批量、并行的計算,極大地提高了CPU的利用效率。
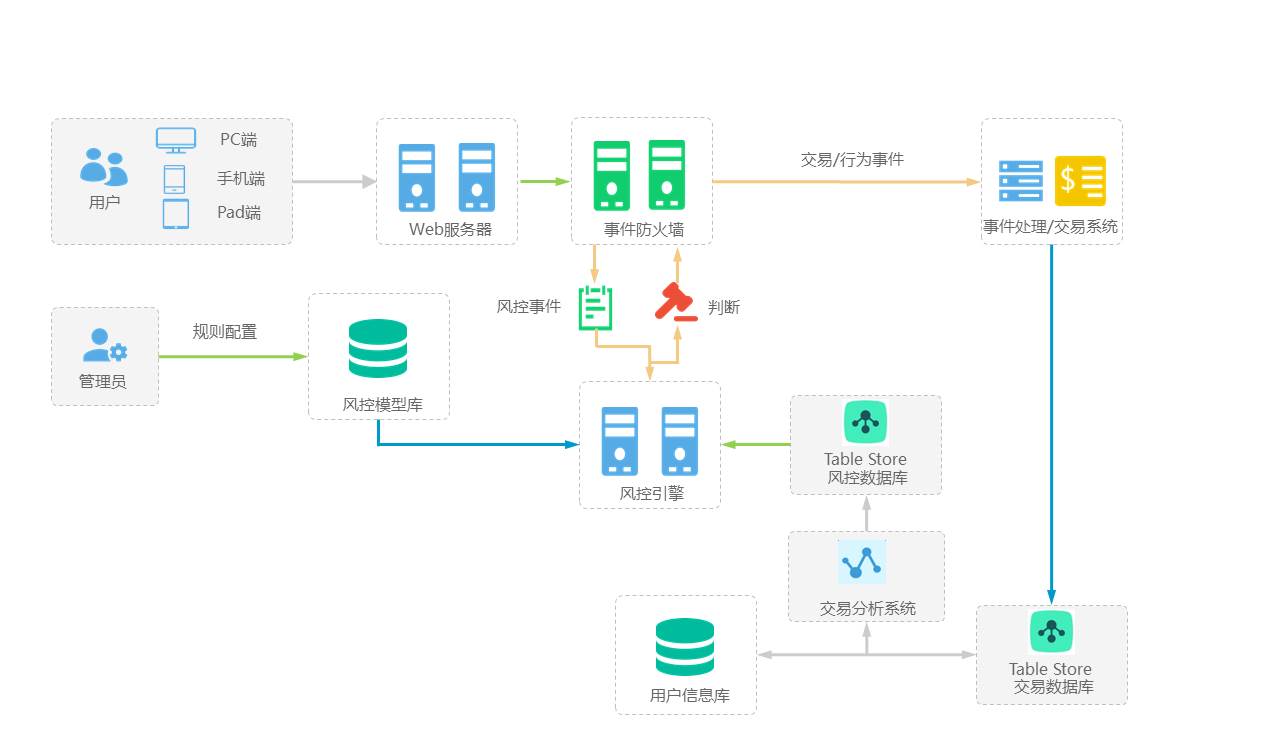
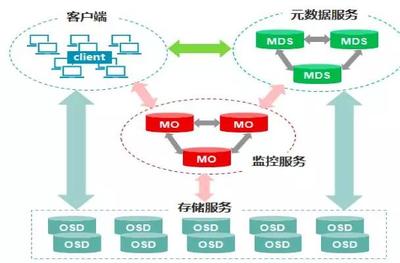
在分布式架構上,他們摒棄了傳統的主從復制與分片中間件模式,研發了一套基于共識協議(如Raft)的真正原生分布式數據庫內核。這套架構實現了數據的自動分片、負載均衡與無縫彈性伸縮,不僅保證了強一致性,更通過多副本并行處理與智能路由,將跨節點查詢的延遲降至最低。
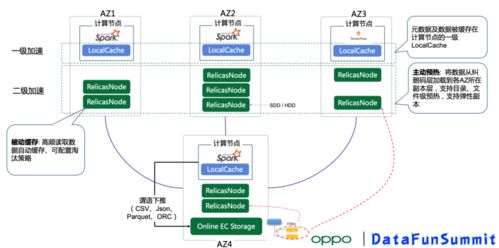
他們還為云原生環境做了深度優化。數據庫服務被設計為微服務集合,能夠無縫部署在Kubernetes等容器平臺上,實現資源的按需分配與隔離。結合智能運維與AI驅動的調參系統,數據庫能夠根據實時負載動態調整配置,始終保持在最佳性能狀態。
經過一系列 benchmarks 與真實場景的檢驗,這套全新的數據處理與存儲服務系統,在典型的混合負載(OLTP+OLAP)場景下,性能指標達到了原有主流商業數據庫的百倍以上,同時保持了極高的可用性與易用性。
這位數據庫老兵的創新之路證明,在大數據時代,性能的飛躍依賴于對經典理論的傳承、對新技術的融合,以及敢于重構核心的勇氣。他的故事啟示我們,數據處理技術的屬于那些既能扎根深厚積累,又能勇敢破界創新的探索者。這場性能革命,不僅是一個數字的突破,更是整個數據基礎設施向更智能、更高效時代邁進的關鍵一步。
如若轉載,請注明出處:http://m.leapsoul.cn/product/22.html
更新時間:2026-06-03 07:14:46